Syncing Postgres to Elasticsearch using Kafka + Debezium Connect + Search Worker
I need to keep Elasticsearch indexes in sync with rich domain entities living across multiple tables. This post covers the design I landed on, the approaches I rejected and why, and what this architecture costs you — because it isn’t free and for a lot of systems it’s the wrong call.
The short version: I use Debezium CDC events as triggers, not as the data. A small worker consumes the change events, re-queries the DB for the full denormalized aggregate, and indexes it into Elasticsearch. No Kafka Streams, no stream joins, no rebuilding aggregates from event fragments.
Example repo: zachbroad/debezium-elasticsearch-cdc
The actual problem
Here’s the constraint that drives everything: my application is not the only writer to this database
- The main API writes to it
- Other services have direct DB access
- Humans occasionally touch it directly, usually for one-off support fixes
Application-level indexing only catches writes that go through application code. Every other write path silently drifts the index. You can try to discipline N writers into indexing after every write, but now you’re maintaining N indexing implementations and trusting all of them, forever.
CDC reads the Postgres transaction log. Every committed change gets captured regardless of who made it. That’s the whole argument for this architecture. If it doesn’t apply to you, you probably don’t want this architecture — more on that below.
(Yes, the real fix is “don’t let services write directly to the DB.” Agreed. But this is the system that exists, and CDC works with reality instead of requiring a re-architecture as a prerequisite.)
Requirements
- Rich domain data spread across multiple Postgres tables, denormalized into one ES document per entity.
- No lost updates. Bounded staleness — seconds, not hours. (Note this is not strong consistency. Anything flowing through Kafka is eventually consistent.)
- Fault tolerance: if the worker dies mid-batch, nothing is lost. Kafka offsets aren’t committed until the index write succeeds.
- A reconciliation job as a safety net, not a sync mechanism. It exists to detect drift, and in practice it should find nothing.
Quick primer
- Debezium: a change data capture (CDC) platform that streams row-level DB changes from a RDBMS into Kafka topics by reading the DB’s transaction log.
- Change Data Capture (CDC): the technique of detecting and capturing every change made to a database so those changes can be propagated to other systems in real time instead of periodic batch syncs
- Apache Kafka: a distributed event streaming platform
- Elasticsearch: a distributed search and analytics engine built on Apache Lucene
The stack
- Postgres 18 – any other DB will work, just swap the Debezium source connector.
- Elasticsearch 9.1
- Debezium Connect
- Debezium connector for PostgreSQL
- Apache Kafka (in production I used Azure Event Hub which has its own set of quirks, more on that later)
- A search worker – you can write this in your language of choice
The simple thing you should probably do instead
For applications where your app is the sole writer, just index from your application code. Save the entity, push the document to ES in the same code path (after commit). Done.
This is the pattern the Ruby gem Searchkick implements, and it’s used at Instacart scale. Look how clean the index definition is.
class Product < ApplicationRecord belongs_to :department
def search_data { name: name, department_name: department.name, on_sale: sale_price.present? } endendSearchkick was a direct inspiration for my worker’s design. If I were on Rails with a single writer, I’d use it and live with its shortcomings.
If that describes your system, you can stop reading. Seriously.
The pattern breaks down when:
- You have multiple writers (my situation — see above). The gem can’t see writes it didn’t make.
- Dual-write failure modes matter to you. If the app crashes between the Postgres commit and the ES write, the index silently drifts and there’s no log to replay. Best-effort after-commit hooks are exactly that: best-effort.
Approaches I Rejected
The Elasticsearch sink connector
Confluent’s ES sink connector looked like the most straightforward approach: if I can get correctly-shaped documents into a Kafka topic, the sink connector moves them into ES off-the-shelf. No custom code at all.
The problem is the “correctly-shaped” part. My entities span multiple tables; Debezium emits one topic per table with flat row-level events. To get a denormalized document into Kafka, the options are:
- Maintain a denormalized real table in Postgres via triggers and CDC that table instead. You can’t use a materialized view — Postgres doesn’t emit logical replication events for matviews, and you can’t add them to a publication. So you’re writing and maintaining trigger soup, which is its own maintenance tax and moves indexing logic into the database.
A publication in Postgres is an object that defines which tables’ changes get published through logical replication.
- CDC the base tables and rebuild the aggregate downstream with something like Kafka Streams — which is the next section.
Building DDD aggregates with Kafka Streams
This is the officially blessed pattern from the Debezium blog, written by Hans-Peter Grahsl and Gunnar Morling. CDC each base table into its own topic, then use Kafka Streams to join the topics and emit a denormalized aggregate.
It initially read to me like “the right way to do things.” Here’s why I didn’t do it:
Cross-topic ordering doesn’t exist. A single Postgres transaction touching three tables becomes events on three topics with no transactional boundary connecting them. The Streams join sees them in whatever order they arrive. In practice that means:
- Partial aggregates. The join can fire after the order-row event but before the line-item events land, emitting an aggregate that represents a state the database never contained.
- Foreign-key join complexity. Joining child rows to parents on FK in Streams requires re-keying, state stores for buffering, and careful handling of updates that change the FK itself.
- Deletes are painful. Tombstone propagation through multi-way joins is genuinely hard to get right.
You can solve all of this. People do. But you’re now operating a stateful stream-processing topology whose entire job is reconstructing data that sits, perfectly joined and transactionally consistent, in Postgres — one SELECT away. That asymmetry is what pushed me to the design below.
pgsync
pgsync is purpose-built for exactly this problem: Postgres → Elasticsearch with denormalization defined in a JSON schema.
It’s genuinely good, and I built a working example of it to be fair to it. It reads the same logical replication stream Debezium does, defines the document shape — including nested children through join tables — in a single schema.json, and needs no Kafka. For a greenfield Postgres → Elasticsearch sync it’s probably what I’d reach for first.
Two things ruled it out for this system:
- It’s another single-purpose daemon to operate, with its own Redis checkpoint store. We already run Kafka and Kafka Connect across the platform, so the Debezium route added one connector and one small worker to infrastructure that was already monitored and on-call’d — strictly less new surface than introducing pgsync would have been.
- The document shape is config, not code. pgsync’s JSON schema is expressive, but my projections aren’t always a clean tree walk — some fields are computed, some come from queries that don’t map onto its parent/child relationship model. Owning the “entity id → document” step as a plain SQL query plus a Python projection gave me more room than a declarative schema, and it’s unit-testable without standing anything up.
If neither of those applies to you, pgsync is less code than what follows.
My design: CDC as trigger, Postgres as truth
The core idea: don’t reconstruct the aggregate from event fragments — use the events only to learn that something changed and which entity it belongs to, then ask Postgres for the current state.
Postgres ──WAL──▶ Debezium Connect ──▶ Kafka topics (one per table) │ ▼ Search Worker 1. consume change event 2. resolve event → entity ID(s) 3. SELECT full aggregate from Postgres 4. build denormalized document 5. bulk index into Elasticsearch 6. commit Kafka offsetWhat this buys you:
- No out-of-order problem. It doesn’t matter what order events arrive in or whether you’ve seen all fragments of a transaction. Every re-query returns a transactionally consistent snapshot. Worst case, an “early” event causes you to index state that’s newer than the event — which is fine, because the later events will trigger a re-index of the same (or newer) state. The operation is idempotent.
- The mapping logic lives in one place, in normal code. Event-on-table-X → entity IDs is a function. Entity ID → ES document is a query plus a projection. Both are unit-testable without a Kafka cluster.
- Deletes are easy. Re-query returns nothing → delete the document.
- Coalescing for free. A burst of changes to the same entity collapses into one re-query and one index write if you debounce by entity ID within a consumption batch.
The cost is read amplification: every change event becomes a Postgres query. For my write volume this is a non-issue; if your write rate is high enough that re-query load on Postgres matters, this trade-off needs actual measurement, and the Streams approach starts earning its complexity.
Here’s how the worker in the example repo actually does each step.
Event → entity id. Each topic resolves to a set of affected product ids in one function:
products→ the row’s ownid.reviews→ the row’sproduct_id.brands→SELECT id FROM products WHERE brand_id = ?(a brand rename fans out to every product carrying that brand name).categories→ a recursive CTE down the category tree, then every product in that subtree.
For deletes the row only exists in the event’s before image, but the same id resolution applies. This is the only place that knows the shape of the graph, and it’s a pure function of (table, row) — trivial to unit-test.
Debounce. Dirty ids accumulate in a set and flush after a 500ms quiet window. A brand rename that touches a thousand products becomes one re-query and one bulk request, not a thousand.
Re-query + bulk index. On flush, one SELECT rebuilds the full denormalized aggregate for all dirty ids at once (brand name, category path, average rating, review count), and the docs go to ES via the bulk helper. Any dirty id that the re-query doesn’t return is a product that no longer exists in Postgres — that becomes a bulk delete.
Versioning. Every document is written with version_type=external_gte and a version equal to the Postgres WAL position (pg_current_wal_lsn()) read at fetch time. A slow or replayed write carrying an older WAL position is rejected by Elasticsearch with a 409, so a stale re-index can never clobber a newer document. 404s (deleting an already-gone doc) and 409s are expected and ignored; anything else fails the batch.
Offsets last. Kafka offsets are committed only after the bulk write succeeds. Crash mid-batch and you reprocess those events on restart — harmless, because the worker re-fetches current state rather than applying deltas.
Initial backfill. Debezium’s snapshot.mode=initial emits a synthetic insert for every existing row on first connect, so the index populates itself the same way ongoing changes do — no separate backfill script.
Seeing it work
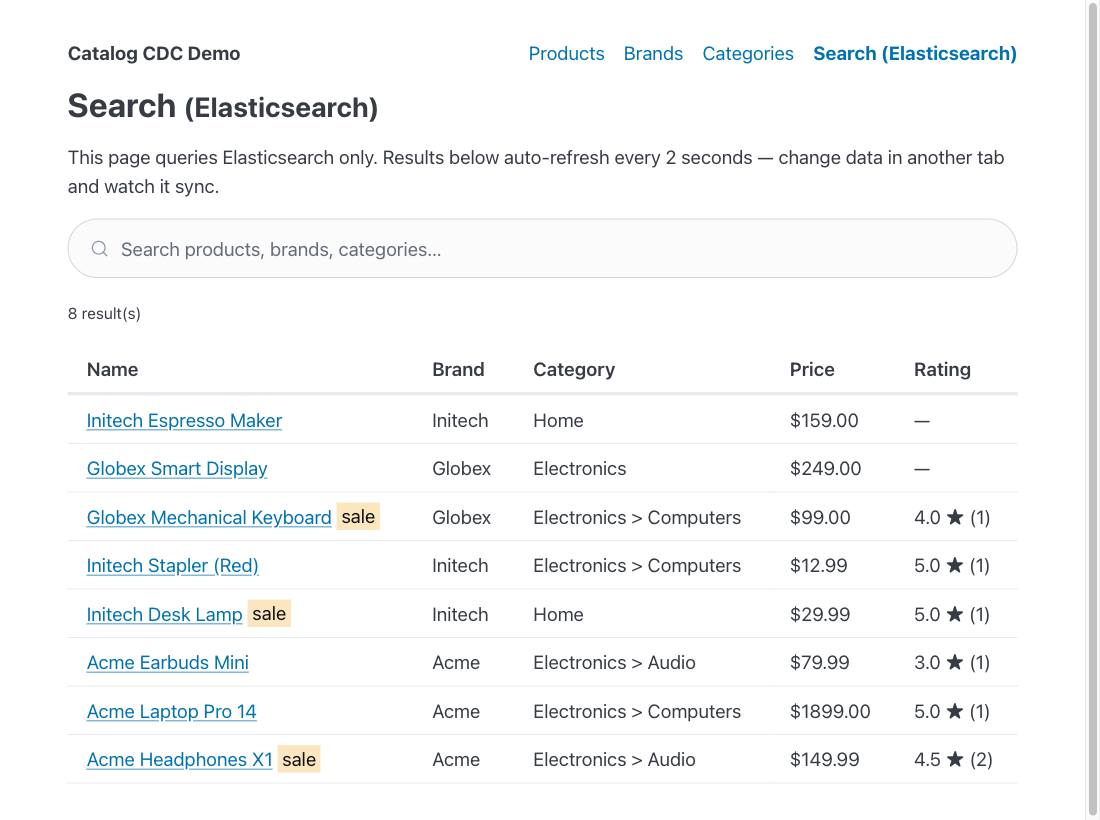
The example repo ships a tiny CRUD app to drive the pipeline. The search page reads only Elasticsearch and auto-refreshes every couple of seconds:
The brands page writes only to Postgres — it has no indexing code at all:
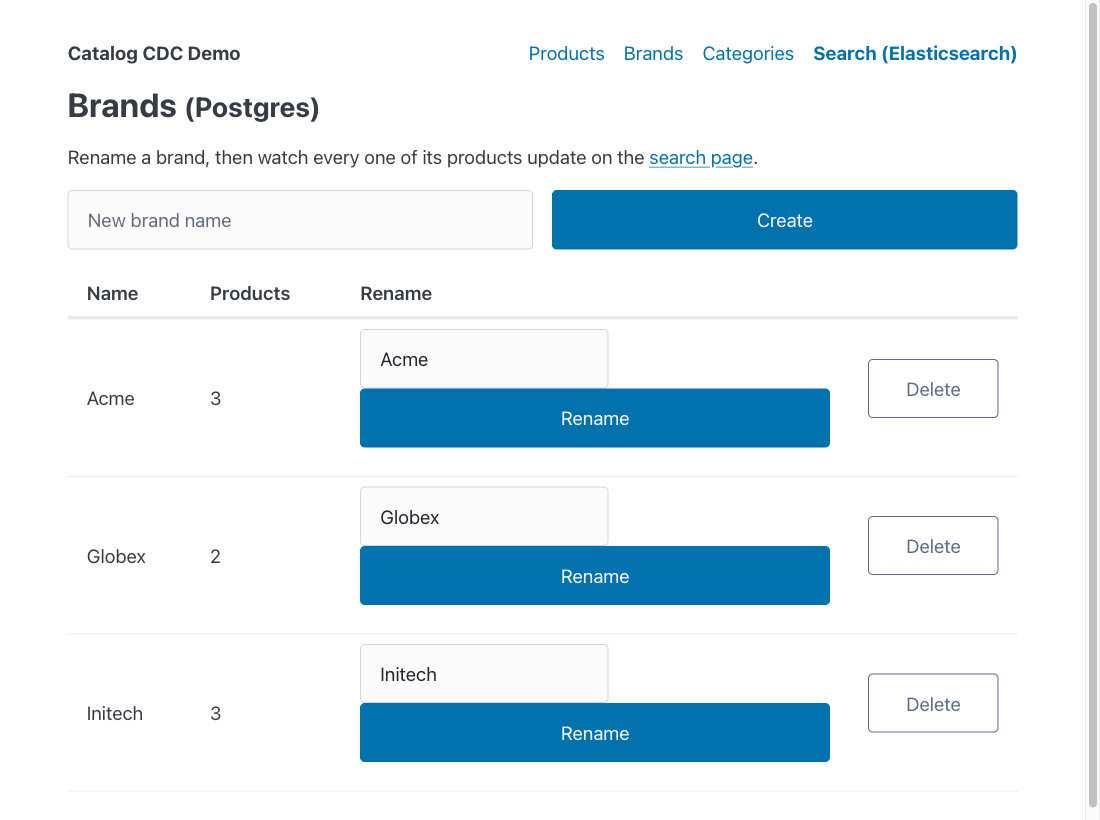
Rename Acme on the brands page and within about a second all three Acme products re-index in the search tab — a one-row update to brands fanned out, through the WAL, into every product document that denormalizes the brand name. Nothing in the app did that; the worker did, off the CDC stream.
Components of this architecture
- Your source database
- Debezium Connect
- Kafka
- Search Worker
Source database
Plain Postgres with wal_level=logical. The example schema is a four-table aggregate — brands → categories → products → reviews — where a product document denormalizes its brand name, full category path, and review stats. The only CDC-specific object is a publication naming the tables to capture:
CREATE PUBLICATION cdc_publication FOR TABLE brands, categories, products, reviews;Nothing else in the database knows the pipeline exists. No triggers, no denormalized mirror table, no indexing columns.
Debezium Connect & Kafka
Debezium reads that publication via pgoutput and emits one topic per table (cdc.public.brands, cdc.public.products, …) with flat row-level events. Kafka is just the durable buffer between Debezium and the worker — it’s what lets the worker die and catch up later, and what makes offset-after-write give at-least-once delivery. The connector config is a single JSON document registered against Connect’s REST API.
Search Worker
This is the only component that knows what a document is: the index name, its field mapping, which table is the root entity, and the primary key. It owns two functions — “event → affected entity ids” and “entity ids → documents” — and the consume/debounce/re-fetch/bulk-write loop around them. Everything in the implementation section above lives here. It’s a few hundred lines of ordinary Python you can read top to bottom, and the same flush() it uses for live changes is reused by the reconciler for full sweeps.
Closing
Azure Event Hubs quirks
In production, “Kafka” is Azure Event Hubs with the Kafka surface enabled. Mostly it just works, but:
- No log compaction. Event Hubs only does time/size retention, not Kafka’s
cleanup.policy=compact. Kafka Connect’s internal topics (connect_configs,connect_offsets,connect_statuses) require compaction — they’re meant to keep the latest value per key forever. The practical answer is to keep those internal topics on a real Kafka and point only the data topics at Event Hubs, or accept that you must externalize Connect’s state. This is the single biggest gotcha. - Topics aren’t auto-created.
auto.create.topics.enableisn’t a thing; every event hub (topic) has to be provisioned ahead of time, with its partition count chosen up front. - Partition count is immutable. You can’t repartition an existing event hub after the fact, so size for peak before you start. Debezium keys events by primary key, so per-key ordering survives, but you don’t get to re-shard later.
- Throughput-unit throttling. Exceed the provisioned TUs/PUs and the broker returns throttling errors rather than just slowing down; Connect and the consumer back off, which shows up as lag spikes, not failures.
- Retention is the floor on worker downtime. Standard tiers cap retention at a few days. If the worker is down longer than that, the events are gone from Event Hubs and the streaming path can’t catch up — which is exactly the hole the reconciler exists to close.
What this costs (read before copying)
Be honest about the bill:
- Debezium Connect is another distributed system you operate. Connector crashes, snapshot behavior, slot management.
- Replication slots can bite you. An abandoned slot will happily retain WAL until your disk fills. Monitor slot lag.
- Schema changes now have a second consumer. Every migration needs a “what does the pipeline do with this” thought.
- Backfills/snapshots are their own project. Initial sync of a large table through CDC is not trivial.
- More on-call surface. Connector down, consumer lag, ES bulk rejections — all new alert categories.
- A reconciliation job to verify Postgres and ES agree. Again: safety net. If it ever finds drift, that’s a bug to fix in the pipeline, not a mechanism to lean on.
If your app is the only writer and a few seconds of best-effort sync is acceptable, the Searchkick pattern is less code, less infra, and fewer 3am pages. This architecture earns its keep specifically when the database has multiple writers and the transaction log is the only complete record of change — and partly because Kafka was already running in our platform, so the marginal infrastructure was one connector and one worker, not three new systems.
What makes this problem genuinely hard
It’s not any individual component — it’s that the obvious composition of off-the-shelf parts (CDC → sink connector) assumes flat tables, and the officially blessed pattern for non-flat data (CDC → Streams → sink) forces you to reconstruct, outside the database, consistency guarantees the database already gives you. The trick is noticing you’re allowed to just ask the database.